Projects
Streamlining Task Deployment on Crowdsourcing Platforms (NSF CAREER AWARD)
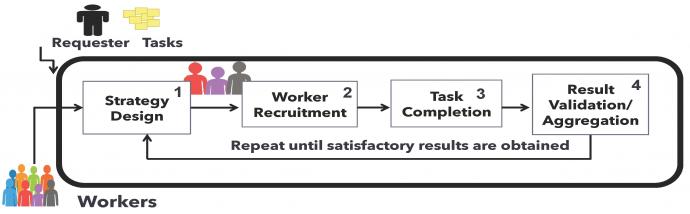
Crowdsourcing leverages online infrastructure to tap an under-explored and richly heterogeneous pool of human knowledge and cognition for solving a variety of tasks that are otherwise considered hard for machines to solve alone. Crowdsourcing systems are built on private or public platforms and are a popular means of deploying a variety of tasks that require human intelligence. Task deployment on crowdsourcing platforms requires identifying appropriate deployment strategies to satisfy deployment parameters, provided by requesters as thresholds on quality, latency, and cost, and also requires analysis of the workforce that is available to undertake the deployed tasks. To date, task deployment remains a painstakingly manual process, as there is little to no help for requesters in deciding how to organize the workforce, in what style, and in what structure to satisfy deployment parameters. Consequently, requesters and workers are mostly confined to one platform, as there is no easy portability of deployment processes across platforms. This project investigates a middle layer that sits between multiple stakeholders in a crowdsourcing ecosystem to aid requesters in deploying crowdsourcing tasks by allowing easy and flexible specification of deployment constraints and goals, and then recommending deployment strategies based on those specifications. Development of this framework thus enables the portability and reuse of deployment processes across platforms.
Advanced Upstream Data Analytics for the Shipyard Schedule Optimization and Planning Project (Office of Naval Research)
Periodic maintenance and modernization of naval vessels are conducted in the shipyards. According to a recent article published by the U.S. Government Accountability Office (GAO), during the fiscal years 2015 to 2019, “the Navy’s four shipyards completed 38 of 51 (75 percent) maintenance periods late”, causing late return to the fleet. A naval vessel’s late return to the fleet results in a decrease in operational readiness due to the reduced number of operational days available for these vessels and impacts on other vessels assigned to support the same or a complementary mission. There exists more than one interdependent factor that contributes to scheduling complexities. Enabling predictive analytics for the yard scheduling problem has to go through a full data science pipeline that contains extensive upstream tasks for data conditioning and assessment before being subjected to advanced analytics and modeling (refer to Figure 1 that shows the full data science pipeline). The goal of this project is to enable upstream data science capabilities that aids downstream AI/ML or predictive analytics to quantitatively achieve CNO availability process milestones.

A Humans-in-the-loop Optimization Framework for Designing Derived Attributes in Data Science (NSF CISE CORE PRO'GRAM)
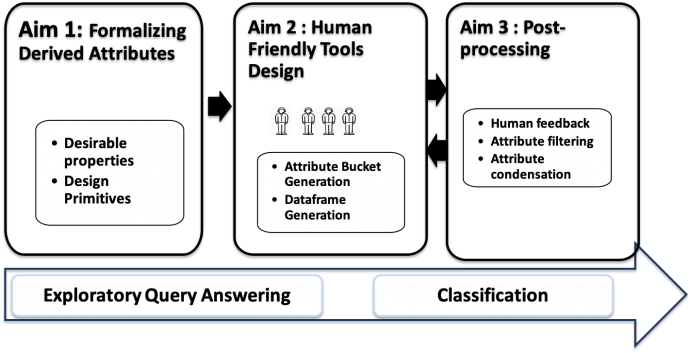
Attribute design is one of the most challenging aspects of the Big Data Science pipeline, where raw attributes need to be transformed into easily-interpretable attributes that can aid data scientists in ad-hoc data exploration and building predictive models. Unfortunately, current automated techniques for attribute design do not offer adequate interpretability to the end user, and attribute designed by human data scientists is painstakingly slow and heavily reliant on domain expertise. This project will develop a novel and transformative approach to enable an ensemble of amateur human workers to be involved in the computational loop for attribute design. It will benefit various domains that require effective applications of Big Data Science.
The research involves developing a suite of algorithms and techniques for understanding the opportunities and challenges of involving an ensemble of human workers in attribute design, which is inspired by ensemble methods in Machine Learning. The main focus is on iterative methods to guide amateur human workers even with limited domain expertise to suggest new attributes for data exploration and predictive modeling. The research makes fundamental advancements to engineering by integrating theoretically-proven attribute design algorithms with application-specific details of real-world data science tasks. A prototype will be rigorously evaluated involving datasets from several application domains and human workers. The outcomes of this research will spur significant research in next generation human-in-the-loop computing, as well as impact data exploration over huge, high dimensional and unfathomable datasets.
PPoSS Planning Grant: Streamware - A Scalable Framework for Accelerating Streaming Data Science, (National Science Foundation)
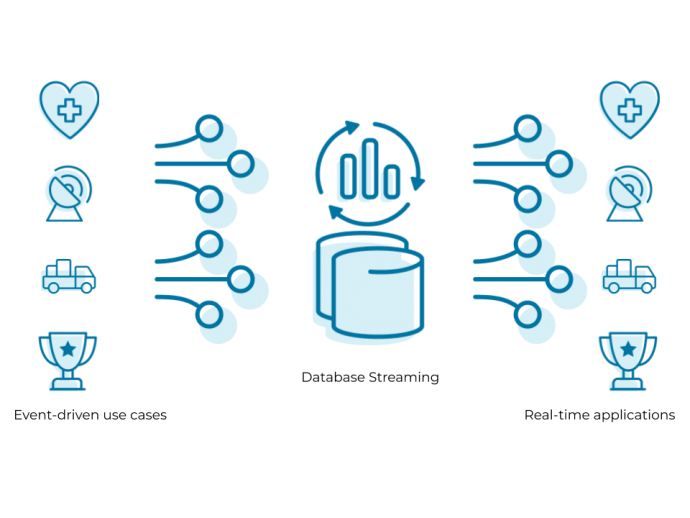
Modern data-science applications are characterized as being highly decentralized, distributed and requiring composition and orchestration between localized analytics on thousands or millions of edge platforms and massive centralized analytics in cloud/data centers, as well as requiring real-time analytics on streaming data. To enable scalable performance of grand-challenge streaming data-science applications, a framework that allows developers to seamlessly build these applications targeting a wide variety of scalable systems is needed. This planning project is conducting preliminary research towards a large proposal for developing an open source framework, StreamWare, that will enable users to develop streaming data-science applications.
point to this website: https://streamware.org/
An Optimized Human-Machine Intelligence Framework for Classification (NSF CISE CORE PROGRAM)
The goal of this project is to develop an optimized human-machine intelligence framework for single and multi-label classification problems through active learning. The focus is on citizen science based cyber-human systems that collect species observation information for ecological applications, but the findings will apply more broadly. It will adapt several existing active learning techniques for single and multi-label classification, but study them in the context of crowdsourcing, especially considering worker-centric optimization. The innovations lie in systematically characterizing variables to model human factors, designing optimization models that appropriately combine system and worker-centric goals, and discovering innovative solutions. The project describes an iterative framework that judiciously employs human workers to collect labels, which, in turn, are used by the supervised machine algorithms to make intelligent predictions.
 |
 |
 |
Human-AI symbiosis (OFFICE OF NAVAL RESEARCH)
The key goal of this project is to enhance the synergy of hybrid human-machine teams to become more effective units, achievable via efficient multi-objective optimization algorithms for agile mission planning. The objective is to provide proactive, context-dependent decision support with enhanced operational capability under uncertainty, time pressure and resource constraints. The proposed decision support capabilities are applicable across a broad range of Navy-relevant missions impacted by uncertainty, such as ship/helicopter/UAV/submarine/aircraft carrier strike group routing, multi-domain battle management, and unmanned system coordination.
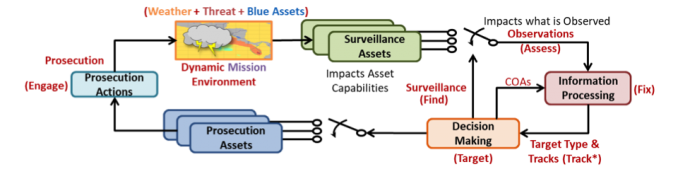 |
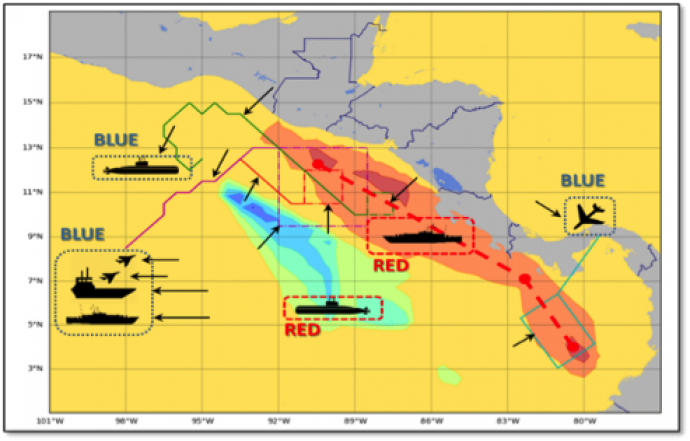 |
Healthcare Analytics
We investigate a variety of compelling and novel research problems that are likely to make deep impacts in the future of health-informatics research. Some examples include, how to design sophisticated data mining algorithms to enable predictive analytics on health outcomes (such as, predict the risk of readmission), design decision support framework to optimize certain health outcomes (minimizing readmission risk, mortality, length of stay, or a combination). We have proposed principled data mining solutions, such as classification algorithms, various generative and discriminative models, as well as statistical analyses and sampling techniques. The solutions are designed by analyzing a variety of high dimensional large-scale data sources, such as clinical data from EMRs, available nation-wide inpatient datasets, and different types of unstructured data. We have used big data infrastructure, such as Hadoop and Map Reduce to enable large-scale data analytics, as well as, cloud-based solutions.

